AWS의 Lightsail은 쉬운 버전의 클라우드이다. 클라우드가 기능이 점점 강화되어가면서 설정해야 하는 옵션은 점점 더 많아지고 콘솔은 복잡해지기만 하자 AWS에서 순한맛으로 내 놓은 서비스인 것이다.
기본적으로 AWS의 서버인 EC2, 데이터베이스인 RDS, 로드밸런서인 ELB 등의 대표적인 서비스들을 엮어 기본적인 설정을 다 넣어놓고 사용자들은 고민 없이 편하게 쓸 수 있도록 해 놓은 것이다. 하지만 그런 만큼 클라우드 특유의 유연성은 크게 떨어진다. 마치 예전의 가비아, Cafe24 등의 호스팅 업체에서 서비스하던 "가상 서버 호스팅"과 흡사하다. 기존의 가상 서버 호스팅은 경쟁 과정에서 편의 기능을 하나씩 추가해나갔다면 Lightsail은 클라우드 서비스에서 여러 기능들을 죽여놓고 숨겨놓은 방식이었기 때문에 오히려 되어야 할 것이 안 되고, 디테일이 부족해 불편할 때가 많다.
기존에 Lightsail을 이용해 시범적으로 운영해본 사이드 프로젝트가 있다. 조금 놀려놓고 있던 서비스이다 보니 관리가 소홀했던 것도 사실이다. 그러다가 갑자기 서비스 장애가 발생하여 확인해보니 DB 용량이 가득차서 DB 서비스가 중단된 것이었다. 클라우드니깐 이런저런 편의 옵션들로 쉽게 복구가 되겠지 싶었으나 생각보다 너무 많은 삽질을 하게 되어서 이 과정을 복기하는 차원에서 간단히 공유해보고자 한다.
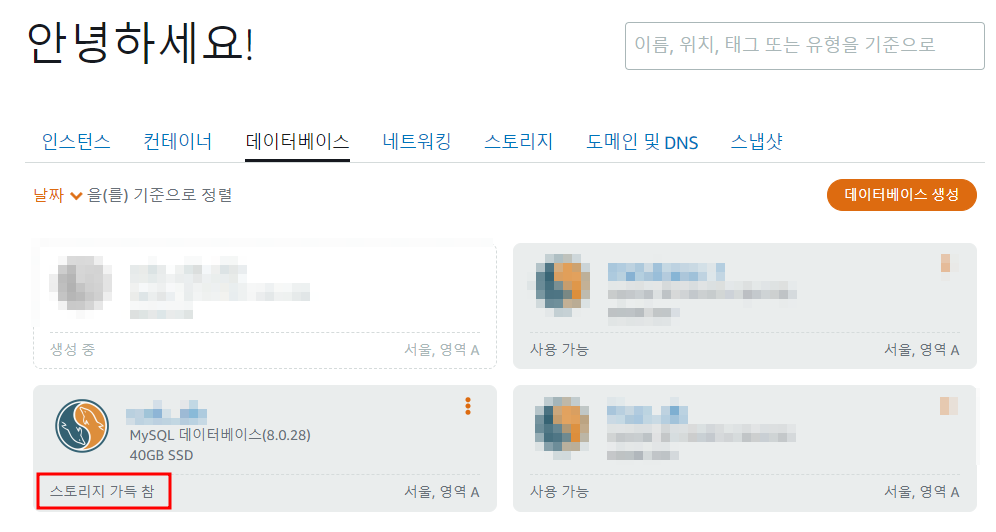
위 스크린샷은 라이트세일에 생성되어 있는 데이터베이스 목록이다. 데이터베이스 중 하나가 "스토리지 가득 참" 상태인 것을 알 수 있다.
아래는 인스턴스를 클릭했을 때 나오는 화면이다. "중지" 버튼이 있는 것을 보니 마치 가동 중인 것 처럼 보이지만 사실상 이 데이터베이스는 아무 기능도 하지 못하는 죽은 DB이다. 쓰기 뿐만 아니라 읽기도 안 되고 로그인도 안된다. 용량이 가득찼기 때문에 DB 사용이 일시적으로 불능이 되는 것 까지는 이해가 된다. 그런데 차라리 DBMS에서 쓰기 불능 상태에 빠지는 정도라면 불필요한 데이터를 지우고 용량을 확보라도 해보곘지만 AWS에선 이게 안된다. 아예 Shutdown을 시켜버리기 때문이다.

우선 데이터베이스를 서버에서 분리하고 재기동을 시도해 보았다. 그러면 다시 상태가 바뀔까 싶었다. 그런데 여기서부터 상당히 당황스럽다. 스토리지가 가득찼기 때문에 재기동도 안되고 심지어 중지도 안 된다.


스냅샷을 생성하여 다른 데이터베이스 인스턴스로 띄워보려고 하였다. 그런데 그것도 안된다. 데이터베이스 스토리지와 스냅샷 스토리지는 분명 구분이 되어 있을텐데 데이터베이스 용량이 가득찼다고 스냅샷 생성이 안된다니!

좀 검색을 해보니 이 경우엔 스냅샷 기능 아래에 있는 비상복원 기능을 사용해야 한다고 한다. 5분 단위로 시간을 선택해서 해당 시간대 데이터로 복구할 수 있다. 얼추 유용하게 쓰일 수 있는 기능을 잘 만들어놓았다고 생각한다. 그런데 이 기능도 보기만큼 쉽게 사용 가능한 것은 아니다.
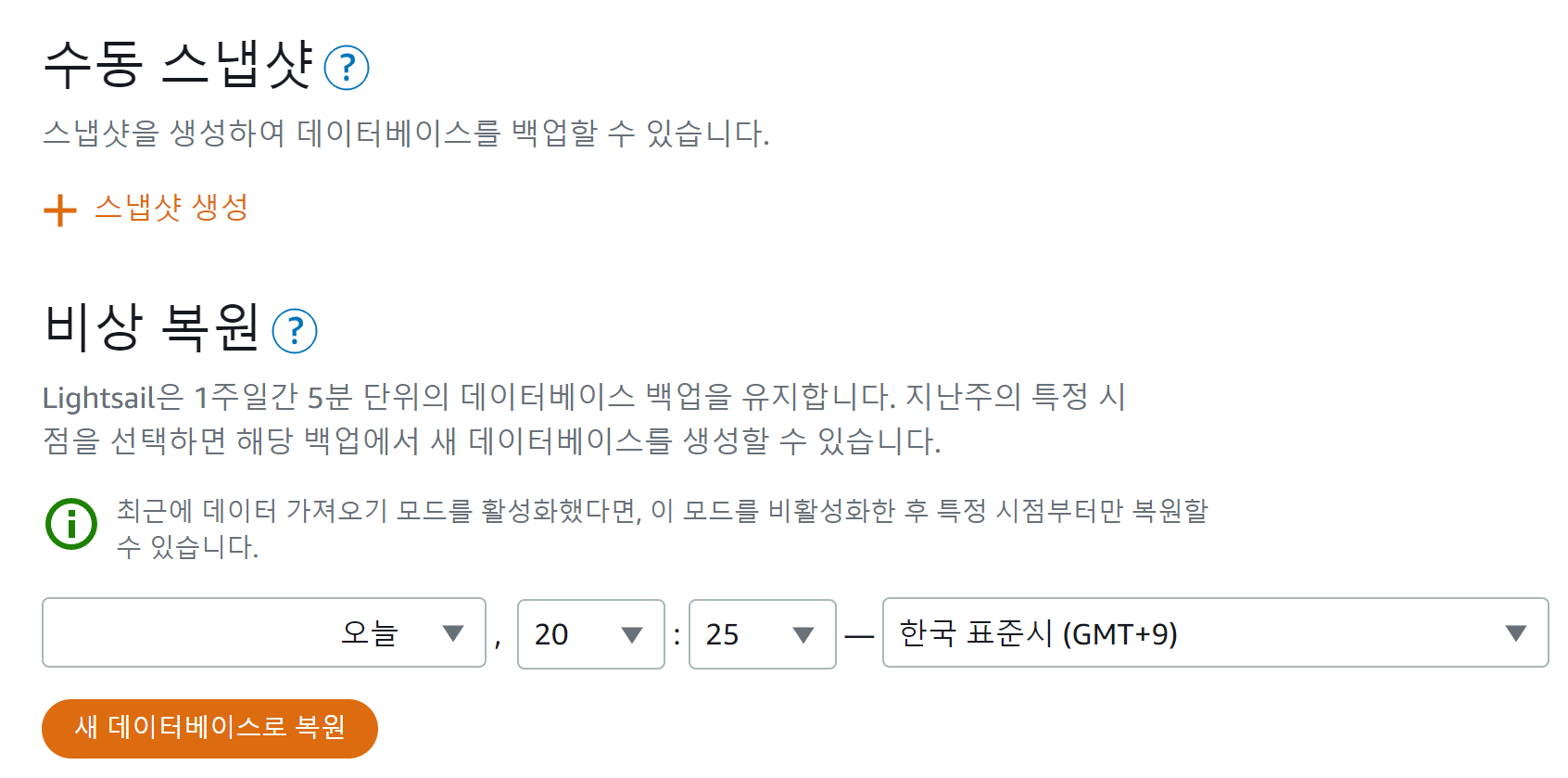
가장 최근 시간대 기준으로 복구를 하려고 하면 아래와 같은 오류가 발생한다. lastRestorableTime 이전의 시간으로 설정을 해야 한다고 에러가 난다. 이 메시지는 lastRestorableTIme에 관한 추가 정보가 없이는 여러가지로 해석될 수 있다.
예를 들어 "lastRestorableTIme은 기다리면 변하나? 지금이 17:10인데, 17:05으로 복구를 하려고 하면 에러가 나고 16:00으로 복구를 하려면 복구가 된다. 복구 가능하게 되는데까지 걸리는 시간이 1시간인가? 그럼 1시간을 더 기다리면 17: 05분으로도 복구가 가능할까?" 라고 생각하는 것도 전혀 무리는 아니다.

하지만 나중에 확인한바에 따르면, 저 lastRestorableTime은 Storate-full 상태가 되면서 서버가 중단되어 이미 그 중단 시점에 고정되어 버린 상태였다. 즉 기다리고 말고 할 것 없이 중단 시점 이전 시점 시간대를 골라줘야 하는 것이다.
그렇다면 최소한 lastRestorableTIme이 언제인지 보여주거나, 저 비상복원에서 고를 수 있는 시간대를 그 이전 시간대로만 선택 가능하게 해줘야 하는게 아닌가? 라는 불편한 생각이 확 든다.
lastRestorableTIme를 정확히 확인하려면 콘솔에 들어가서 명령어를 쳐야 한다. 그러려면 콘솔도 세팅이 되어 있어야 하기 때문에 일단은 급한대로 지표로 분석을 해보았다.



연결 수를 보면 6시 40분 ~ 7시 사이부터 접속이 없어진 것을 확인할 수 있었다. 네트워크 수신 처리량도 비슷한 시간대부터 없어졌다. 로그를 봐도 6시 59분에 shutdown되었다는 정보를 확인할 수 있었다. 그래서 그 이전 시간대를 기준으로 복원을 하기 위해 6시 55분 시점으로 복구 지점을 잡고 새로운 인스턴스를 생성하기로 하였다. 이렇게 하니 오류 없이 생성이 진행되긴 하였다.

용량이 가득찼기 때문인지 같은 용량의 인스턴스로는 생성이 불가능하다. 아예 선택이 되지 않게 되어 있고 두배 가격의 큰 인스턴스부터 생성이 가능했다. 여기서 또 AWS의 상술을 확인할 수 있는 부분은, 한번 큰 인스턴스로 만들어지고나면 더 작은 인스턴스로는 절대 바꿀 수 없다는 것이다. 우선 인스턴스를 생성해서 가동해놓고 더 작은 용량으로 돌아갈 상태가 되었다고 해도 '정책상', '기술적인 문제로' 더 작은 인스턴스로는 마이그레이션이 안된다.
물론 가상 서버 환경에서 다운스케일이 힘들다는 것은 알고 있지만, 불가능하진 않다. 무중단으로는 어렵겠지만 서버가 중단된 상태에서 리소스를 정리하면 가능하다. 아마존의 기술력으로 이게 안된다고 한건 그냥 "정책적"인 결정이라고 생각하고 수익성에 기반한 정책이 아닐까 싶다.
소결론으로, 당신이 데이터베이스 용량 관리를 못해서 Storage-full 상태가 되면 당신은 현재 가격에서 2배가 되는 서비스로 상향을 해야 한다. 이건 일종의 패널티로 보이기까지 한다.

더 심각한 문제가 발생했다. 분명히 용량이 2배(40GB->80GB)가 되는 인스턴스를 생성했는데도 여전히 Stroge-full 상태로 나오는 것이다. 분명 40GB 이상의 여유공간이 있을만한 데이터베이스임에도, 생성하자마자 시작도, 중지도 못하는 깡통이 만들어져버렸다. 혹시나 만들어진지 얼마 안되어서 자기 용량을 아직 인식을 못한 건가 싶어 하루종일 기다려봤으나, 결국 저 인스턴스는 돈만 잡아먹는 쓰레기 깡통임이 밝혀졌다.
혹시라도 내가 지표와 로그를 보고 추정한 lastRestorableTime이 잘못되었나 싶어서(잘못 된거면 아예 복구가 되지 않았어야 하나 싶긴 하지만 AWS에 대한 신뢰가 사라진 상태이다) Documents를 찾아 콘솔 명령어를 파악하여 상태를 조회해보았다. 내가 추정한대로 복구 가능 시간은 06:55분이 맞았다.
[ec2-user@peim ~]$ aws lightsail get-relational-database --relational-database-name OOOO_db
{
"relationalDatabase": {
"name": "OOOO_db",
"createdAt": "2022-05-03T13:37:50.198000+00:00",
:...skipping...
"relationalDatabaseBlueprintId": "mysql_8_0",
"relationalDatabaseBundleId": "micro_1_0",
"masterDatabaseName": "dbmaster",
"hardware": {
"cpuCount": 1,
"diskSizeInGb": 40,
"ramSizeInGb": 1.0
},
"state": "storage-full",
"backupRetentionEnabled": true,
"pendingModifiedValues": {},
"engine": "mysql",
"engineVersion": "8.0.28",
"latestRestorableTime": "2022-12-26T21:55:00+00:00", #한국 시간은 +9 해야함
"masterUsername": "dbmasteruser",
"parameterApplyStatus": "in-sync",
:...skipping...
결국 이건 명백한 버그라는 것이다. 아래 로그를 보면 황당하게도, 기존 장애가 발생한 데이터베이스처럼 인스턴스가 켜지는 와중에 계속 shutdown 명령어가 와서 종료되었다가, 다시 켜지려고 하니 또 shutdown 명령이 와서 결국 중단되는 것을 확인할 수 있다. 뭔가 중단에 관한 flag가 복원 인스턴스로 잘못 전달이 된 거거나, DB가 꼬였거나 여튼 단단히 잘못되었다.

결국 lastRestorableTIme으로부터 점점 과거로 가며 인스턴스 생성을 계속 시도하는 삽질을 하다가 어제 일자로 복원한 데이터베이스 하나를 살릴 수 있었다. RPO가 거의 10시간이다. 복구 기능이 제대로 동작하지 않고 정보도 불친절하여 소모된 시간을 고려하면 RTO도 5시간 이상이다. 이정도면 가상서버호스팅에 mysql 직접 설치해서 사용하는 것보다 전혀 나을게 없다. 차라리 그렇게 했으면 디버깅은 훨씬 수월했을 것이다.
이 과정에서 소모한 시간과 수 만원의 비용은 보상을 받을 수 없다. 데이터 손실에 대해서도 말이다. 고객센터에 테크니컬한 지원을 받으려면 비용을 더 주고 Support Plan을 구독해야 한다. 최저 한화 4만원부터 시작을 하는데, 이것도 가장 낮은 플랜이라 원활하게 서비스를 받을 수 있을지는 미지수이다.

Support Plan에 별도 가입하지 않은 경우는 Basic Plan인 것으로 보는데, 이 경우엔 아마존 고객센터와 직접 소통할 순 없다. 고객센터 페이지에 들어가봐도 이미 만들어진 Documents나 Q&A 검색을 하는 정도밖에 안되고 그래도 안되면 re:Post 라는 지식IN에 질문을 올리라고 하는데 그러면 전문성이 전혀 없는 다른 고객이 답변을 해준다. 정말 지식IN 처럼 경험치(?)를 쌓거나 레벨을 올리는 재미, 또는 선의에 의해 답변을 하는 것인데 답변의 질은 가관인 경우가 많다.
내가 겪은 일도 질문을 해봤으나, 전혀 오해의 소지 없이 40GB에서 80GB로 증설하며 인스턴스를 생성했다고 해도 답변은 "기존과 동일한 용량으로 인스턴스를 생성하면 여전히 용량이 없는 상태이기 때문에 Storage-full로 바로 전환되고 중단될 수 있습니다. 더 큰 용량을 선택하여 인스턴스를 생성하십시오."라는 답답한 답변만 받았다. 정확히는 모르곘으나 경험치를 쌓든 레벨을 올리든 하기 위해서 질문을 보지도 않고 복붙 답변을 하는 것으로 보였다.
아무리 AWS의 기술력이 좋다고 해도 일부 영역에선 아직 부족한 면이 많다. 국내의 서비스 환경에 익숙한 사용자들이라면 아마 큰 불편을 느낄 것이다. 빨리 NCP, NHN 등 국내 CSP들이 성장해서 갈아타기 좋은 서비스들을 많이 내주길 바랄 뿐이다. 걱정되는 것은 네이버가 구글을 따라한답시고 고객센터를 없애고 AWS와 같이 소통이 안되는 형태의 고객센터를 구성하고 있다는 것인데 클라우드 서비스가 아직 불완전한 상황에선 제발 그러지 않았음 좋겠다.
'잡담' 카테고리의 다른 글
| "근기"라는 말 들어보셨나요? 기업에서 쓰는 비표준어 (2) | 2021.08.08 |
|---|---|
| 기술평가 관련 자격증 3가지 - 기술(사업·신용)평가사 (1) | 2021.08.06 |

